
スマートフォンやテレビ、音楽ストリーミングサービスなど、私たちの日常はデジタル音声技術であふれています。しかし「デジタル音声とは何か?」「どのような仕組みで動いているのか?」といった疑問を持つ方も多いでしょう。本記事では、デジタル音声の基本から専門用語、利用例までをわかりやすく解説します
デジタル音声とは
アナログ音声とデジタル音声の違い
- アナログ音声:空気の振動をそのまま波形データとして扱う
- デジタル音声:アナログ波形を数値(デジタルデータ)で表現する
デジタル音声は現実の音をデジタルデータへと変換し、保存・編集・配信など多様な活用を可能にしています
デジタル音声ができるまで:標本化と量子化
デジタル音声とは、実際に私たちの耳で聞いているものをデジタルデータで表現したものです。
音とは、空気の振動によって発生した波が私たちの耳に伝わって音して聞こえています。
デジタル音声は、現実の音声をデジタルデータに変換したものです。この変換には、標本化と量子化という2つのプロセスが用いられます。
標本化(サンプリング)
連続する音声信号から一定間隔ごとにデータを取得します。この間隔の頻度を「サンプリング周波数」と呼び、数値が高いほど細かい音の表現が可能。主な例:
サンプリング周波数が高いほど再現度が高くなりますが、データ容量も増加します。
サンプリング解説図
連続した音声信号を一定間隔でサンプリングし、その時点の音声データを取得することです。このサンプリング間隔はサンプリング周波数と呼ばれ、単位はHz(ヘルツ)です。サンプリング周波数が高いほど、 より細かく音声信号を捉えることができ、高音質になります。
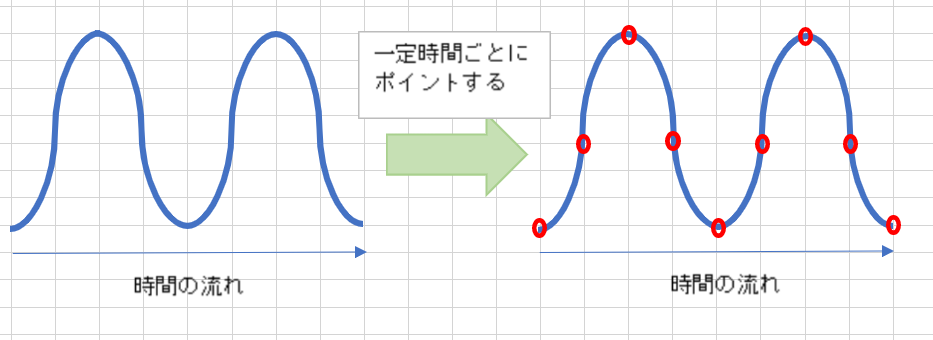
以下はサンプリングしたデータを元の波に戻そうとする流れです。
この点が多いほど、元の波形に近づかせれるので、再現度が高くなります
ただし再現度は上がりますが、データ量が増えますし処理の回数も増えることになります。
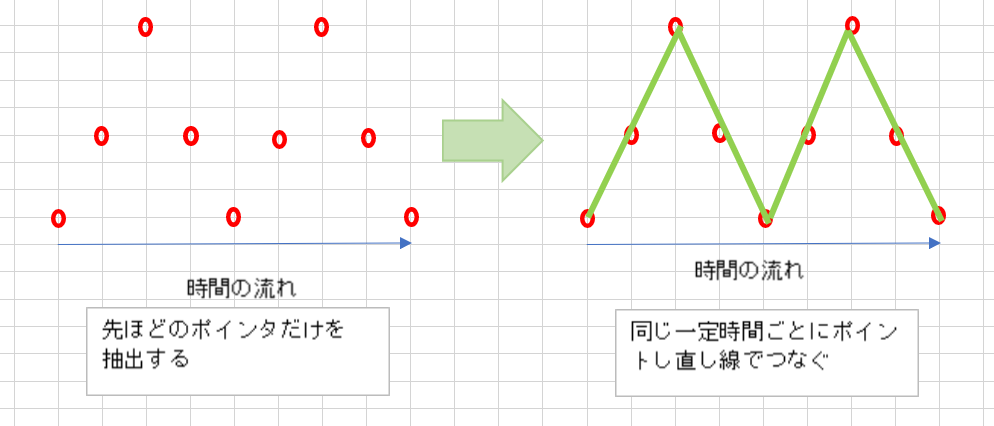
量子化(ビット深度)
サンプリングで取得した音の大きさ(振幅)をあらかじめ設定した段階(レベル)で区切ります。これを「量子化」と呼び、区切りが細かいほど高音質となります。
- ビット深度が高いほど細やかな音の表現が可能だが、データも大きくなります。
量子化解説図
量子化とは、標本化によって得られた音声データを、デジタルデータに変換することです。音声データの振幅(大きさ)を、あらかじめ決められた段階(レベル)に量子化します。量子化の段階が多いほど、より細かく音声デー タを表現でき、高音質になります。
先ほどのポイントだけ示した画像はX軸として時間だけ表現していましたが、Y軸に値を設定します。
今回は、最小値が-3 最大値が3として設定しました。
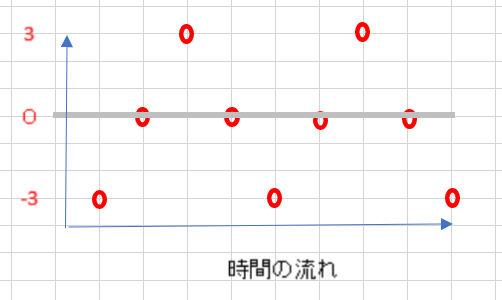
これで、デジタルデータとして表現できます。
今回の場合、-3->0->3->0->-3 ->0->3->0->-3 という風なデータになります。
この波の縦軸に数値を設定し、データ化ができるようにすることを量子化といいます。
最大値と最小値の幅を大きくすればするほど、表現できる幅が広がり細かく値を設定できるので、音がより表現できるようになります。
※ただし、こちらも値を大きくすればするだけ表現の幅は広がりますが、データが大きくなったり扱えないデータ長さになる弊害があります。
このように標本化と量子化を行うことでデジタル音声データは生成されます。
デジタル音声の基礎用語まとめ
- サンプリング周波数(Hz):1秒間に何回サンプリングを行うか
- ビット深度(bit):1サンプルあたりの表現に使われるビット数
- 量子化:振幅を数値で区切りデータ化する処理
- 標本化:アナログ信号から一定間隔ごとに値を取得する処理
デジタル音声の活用事例
現代生活では、下記のような幅広い分野でデジタル音声が使われています。
- 音声アシスタント:Siri、Googleアシスタント、Alexaなど
- 音楽ストリーミングサービス:Spotify、Apple Music、Amazon Musicなど
- 音声通話アプリ・Web会議:LINE、Skype、Zoomなど
よくある質問(FAQ)
Q1. デジタル音声はどうやって再生される?
A. 端末のデジタル信号処理(DSP)によってデータがアナログ信号へ変換され、スピーカーから音として再生されます。
Q2. サンプリング周波数やビット深度が高いとどうなる?
A. より細かく、リアルな音が再現できますが、ファイルサイズが大きくなるため用途によって選択が重要です。
まとめ
デジタル音声は、標本化と量子化という技術を駆使し、私たちの日常をより便利に、豊かにしています。仕組みを知ることで、スマホや音楽配信だけでなく、今後登場する新たな音声サービスもより深く楽しめるでしょう

コメント