
この記事では、OllamaとLangChainを使用して構築した簡単なRAG(Retrieval-Augmented Generation)チャットボットについて解説します。このチャットボットはローカル環境で動作し、特定のドキュメントから情報を検索して回答を生成する仕組みです。
RAGとは?
RAGは、外部データソース(例: 文書やデータベース)から関連情報を検索し、それを元にLLM(大規模言語モデル)が回答を生成するフレームワークです。この手法により、モデルが事前に学習していない情報にも対応できます。
使用した技術スタック
- Ollama: ローカルで動作するLLM(例: “gemma3″モデル)を提供。
- LangChain: RAGパイプラインの構築を効率化するフレームワーク。
- Chroma: ベクトルデータベースとして使用。
- Gradio: ユーザーインターフェースの構築。
実装の概要
以下に、実際のコードとその役割について説明します。
ドキュメントのベクトル化
create_vectorstore関数で、入力ファイルを小さなチャンクに分割し、それぞれをベクトル化してpersist_directoryで指定したフォルダにChromaデータベースを保存します。
def create_vectorstore(filename):
with open(filename, "r", encoding="utf-8") as file:
text = file.read()
your_documents = [Document(page_content=text)]
splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=50)
docs = splitter.split_documents(your_documents)
embeddings = OllamaEmbeddings(model="snowflake-arctic-embed")
vector_store = Chroma.from_documents(
documents=docs,
embedding=embeddings,
persist_directory="./chroma_db"
)
return vector_store質問応答の処理
respond関数でユーザーからの質問を受け取り、RAGチェインを通じて回答を生成します。
def respond(question):
ret = rag_chain.invoke(question)
return ret.contentRAGチェインの構築
以下の手順でRAGチェインを構築します。
- ベクトルストアから関連する文脈(context)を検索。
- プロンプトテンプレートを使用して質問と文脈を統合。
- LLM(Ollama)で回答を生成。
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
llm = ChatOllama(model="gemma3", temperature=0)
prompt_template = """
以下の文脈を使用して質問に答えてください。
文脈: {context}
質問: {question}
回答(日本語で簡潔に):
"""
prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
)ユーザーインターフェース
Gradioライブラリを使って簡単なチャットUIを構築します。
gr.Interface(fn=respond, inputs="text", outputs="text").launch()プログラム全体
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.runnables import RunnablePassthrough
from langchain_ollama import ChatOllama
from langchain.prompts import PromptTemplate
import gradio as gr
from langchain.docstore.document import Document
rag_chain = None
def create_vectorstore(filename):
# ファイル読み込み
with open(filename, "r", encoding="utf-8") as file:
text = file.read()
# LangChainのDocument形式に変換
your_documents = [Document(page_content=text)]
splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=50
)
docs = splitter.split_documents(your_documents)
embeddings = OllamaEmbeddings(model="snowflake-arctic-embed")
vector_store = Chroma.from_documents(
documents=docs,
embedding=embeddings,
persist_directory="./chroma_db"
)
return vector_store
# 実行関数
def respond(question):
ret=rag_chain.invoke(question)
return ret.content
def main():
global rag_chain
file = "D:\\Pythonテスト\\ragchatbot\\input.txt"
vector_store = create_vectorstore(file)
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # レトリーバーの生成
# LLMアクセス用インスタンスを生成
llm = ChatOllama(model="gemma3", temperature=0)
# プロンプト生成
prompt_template = """
以下の文脈を使用して質問に答えてください。
文脈: {context}
質問: {question}
回答(日本語で簡潔に):
"""
prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
# RAGチェインの生成
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
)
# GUIの起動
gr.Interface(fn=respond, inputs="text", outputs="text").launch()
if __name__ == '__main__':
main()使用方法
- 必要なライブラリ(LangChain, Gradioなど)をインストール。
input.txtという名前のテキストファイルに検索対象となるデータを書き込む。- スクリプトを実行すると、GradioによるチャットUIが起動。
- チャット画面で質問すると、関連する文脈に基づいた回答が表示されます。
input.txtは以下のような形で文章をいれます。
第二次世界大戦は、1939年から1945年まで続いた世界規模の戦争であり、連合国と枢軸国の間で行われました。
この戦争はポーランド侵攻をきっかけに始まり、ヨーロッパ、アジア、アフリカなど広範囲で戦闘が展開されました。
戦争の結果として、数千万人の命が失われ、国際社会に大きな変化をもたらしました。
特に国際連合の設立や冷戦の始まりなど、政治的な影響が長期的に及びました。
また、技術革新や社会構造の変化もこの期間中に進みました。実行結果
実行結果は以下のような形になります。
※プログラム実行後にウェブブラウザで表示します。
questionのところに質問内容をいれて、Submitを押すと、しばらくするとoutputに生成AIの回答結果が表示されます。
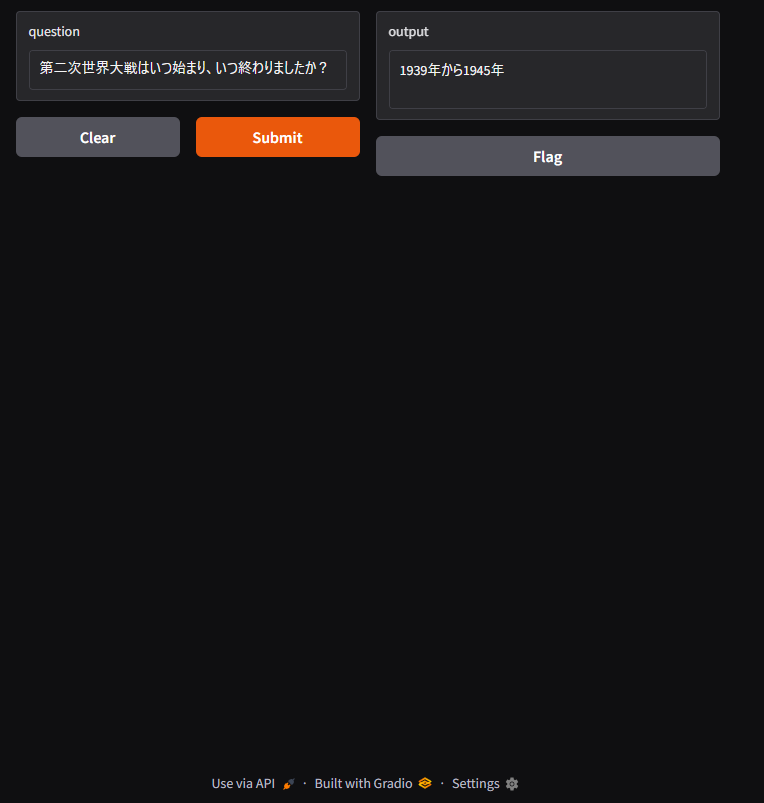
改善案
- 会話履歴の保持: 現在は単発の質問応答のみ対応しています。LangChainのメモリ機能を活用すれば、会話の流れを考慮した応答が可能です。
- 複数ファイル対応: 複数ドキュメントから情報を検索できるよう拡張すると便利です。
- モデル選択肢の拡大: 他のLLM(例: Llama 3やMistral)も試すことで性能向上が期待できます。
まとめ
このプロジェクトでは、OllamaとLangChainを組み合わせてシンプルなRAGチャットボットを構築しました。ローカル環境で動作し、高速かつ柔軟な情報検索が可能です。今後、さらなる機能追加や最適化によって、より実用的なアプリケーションへと進化させることができます。
おすすめのPython学習本を知りたい場合はこちら



コメント